




The News
After ChatGPT released late last year, it quickly made headlines for its ability to take — and often pass — high-level academic exams, including law school tests, the U.S. Medical Licensing Exam, and Ivy League MBA finals.
This week, OpenAI unveiled the new, advanced version of its chatbot technology, called GPT-4, and put the artificial intelligence model to the test before its debut.
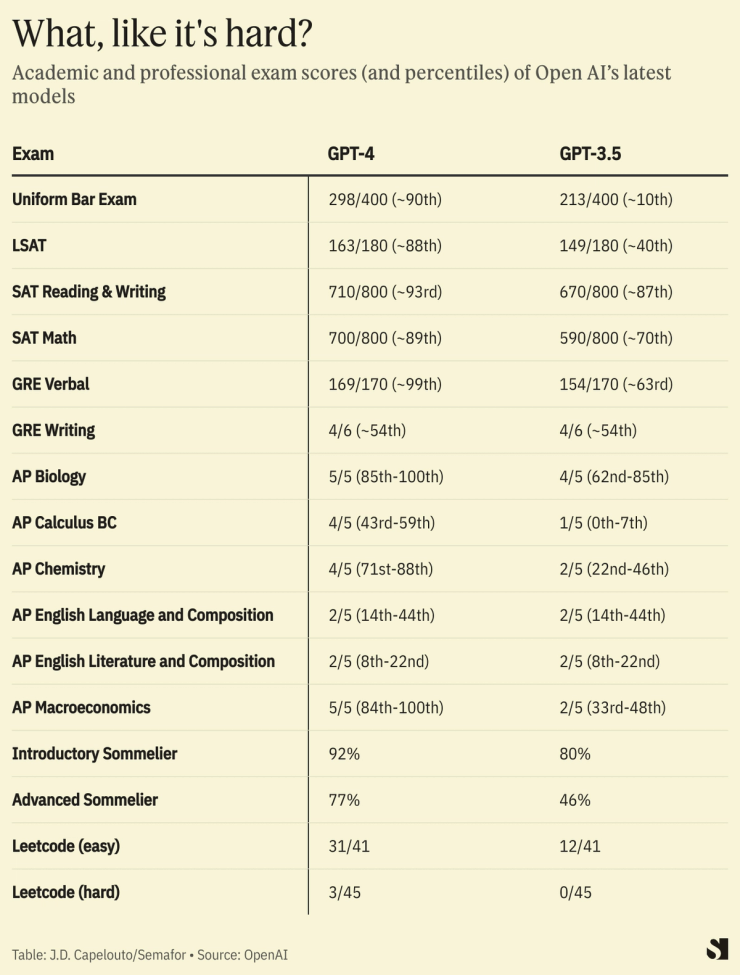
GPT-4 took a wide range of simulated exams, from sommelier assessments to graduate school admission tests. Here’s how it scored, compared to the older model that ChatGPT uses, called GPT-3.5.
Know More
The results show that the new system exceeds ChatGPT’s capabilities on topics like math and verbal comprehension.
For example, while ChatGPT scored a 1 out of possible 5 on the Advanced Placement Calculus BC exam, GPT-4 scored a 4.
And while ChatGPT did poorly on the Uniform Bar Examination, scoring in the lower 10th percentile, GPT-4 scored in the 90th percentile.
However, the new system didn’t do great on tests related to writing.
GPT-4 didn’t improve on ChatGPT’s performance for the AP English Language or Literature exams (it got a 2 out of 5 on both), or the writing portion of the Graduate Record Examination (GRE).
It also didn’t score well on an advanced Leetcode exam, which tests developers’ skills to prepare them for technical interviews.
Rumman Chowdhury, an expert in the responsible applications of AI, pointed out on Twitter that results show the model is “incapable of abstract creativity.” She added, “Humans aren’t replaceable.”
Step Back
GPT-4 was made available Tuesday to paid users of ChatGPT Plus, accompanied by a live demonstration from OpenAI president and cofounder Greg Brockman. He showed how the new model has comprehension and coding abilities beyond what ChatGPT can do.
It also can analyze and describe photos, though that feature isn’t available to the public.
Open AI said the model is safer and more factual than previous GPT iterations. But it has “many known limitations that we are working to address,” OpenAI said, including social biases, adversarial prompts, and hallucinations, which is when a chatbot responds confidently with an incorrect answer.