




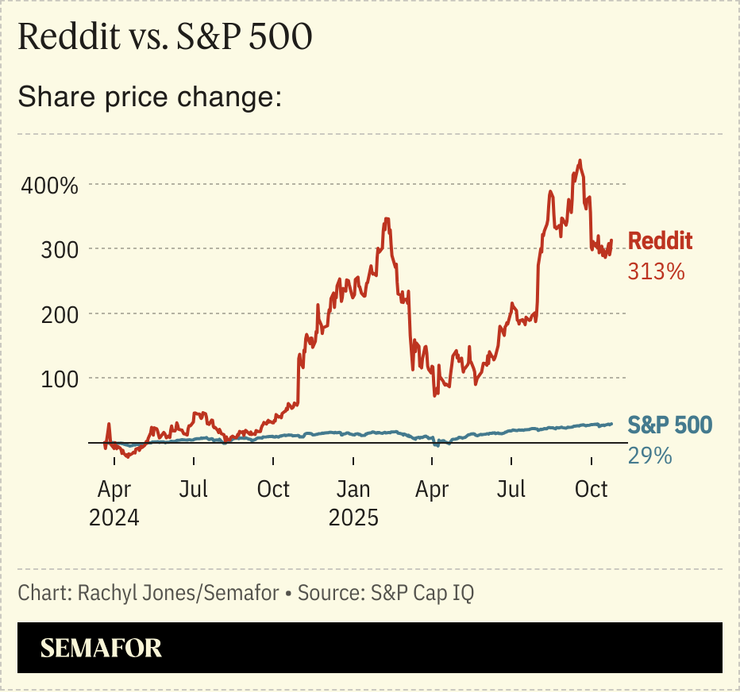
The News
One of the byproducts of the chatbot explosion is the world has come to know the value of Reddit. Google inked a $60 million deal to use the platform’s content to train large language models. And everyone else seems to want it too, even if they aren’t willing to pay for it. Reddit sued Anthropic this summer for training on it without permission.
Reddit data is also coveted by AI search engines. Earlier this week the company filed a lawsuit against a group of data-scraping companies for allegedly pilfering its content and selling it to Perplexity. If the case continues on to discovery, the list of defendants could expand.
Know More
Another interesting wrinkle is that the lawsuit doesn’t allege that Reddit itself was scraped. Rather, the content came from Google searches that included short summaries of Reddit articles. Those summaries then found their way into Perplexity’s search results, the suit alleges. Perplexity denies wrongdoing. Reddit has to show that Perplexity circumvented copyright protections by purchasing the scraped content and that Reddit was harmed in the process.
Scraping the web itself is not illegal, but if it is used as a way to violate copyright protection, the scraper could be found liable. Reddit will have to explain why it’s not harmful to have summaries of its content appear in Google search results (Google doesn’t pay for those), but it is harmful when the content shows up on Perplexity.
Like all of these AI copyright lawsuits, a lot of it comes down to vibes. The internet agreed on behavioral norms. AI is now taking a sledgehammer to them.